注记
侧边栏显示隐藏
教育电商
概率论
客快物流大数据
volatile
下载视频
飞机大战
三星卡刷
三星线刷
fdisk
一卡通数据分析
PEFT
YOLOX
自动装配原理之Starter
vuex
Silicon Labs
证件照
Advisories
三维重建
数据湖
2024/4/11 13:35:58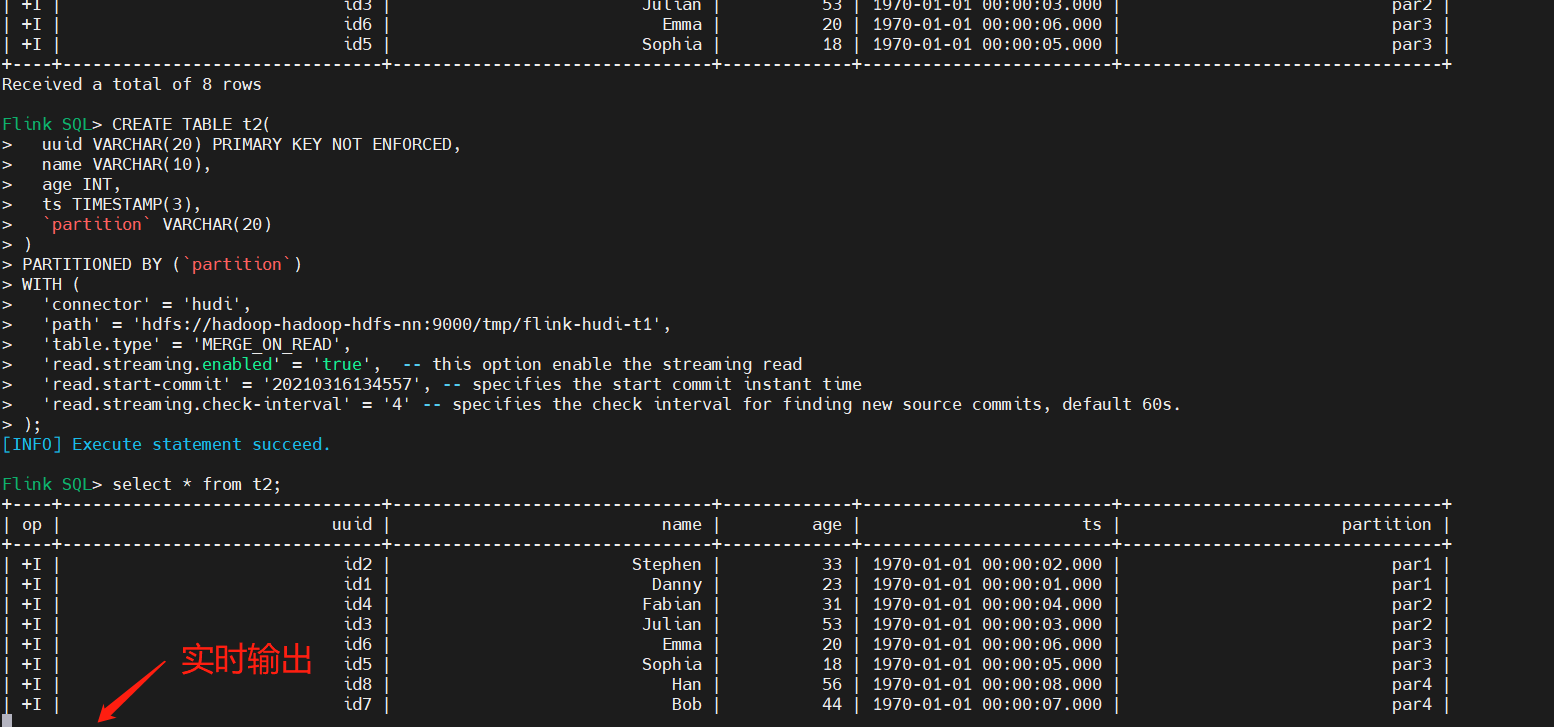
大数据Hadoop之——Apache Hudi 数据湖实战操作(Spark,Flink与Hudi整合)
文章目录一、概述二、Hudi CLI三、Spark 与 Hudi 整合使用1)Spark 测试2)Spark 与 Hudi 整合使用1、启动spark-shell2、导入park及Hudi相关包3、定义变量4、模拟生成Trip乘车数据5、将模拟数据List转换为DataFrame数据集6、将数据写入到hudi四、Flink 与…

Hudi(22):Hudi集成Flink之常见问题汇总
目录
相关文章链接
问题一:存储一直看不到数据
问题二:数据有重复
问题三:Merge On Read 写只有 log 文件 相关文章链接 Hudi文章汇总
问题一:存储一直看不到数据
如果是 streaming 写,请确保开启 checkpoint&a…

5 Paimon数据湖之表数据查询详解
更多Paimon数据湖内容请关注:https://edu.51cto.com/course/35051.html
虽然前面我们已经讲过如何查询Paimon表中的数据了,但是有一些细节的东西还需要详细分析一下。 首先是针对Paimon中系统表的查询,例如snapshots\schemas\options等等这些…
云数据库时代,AWS凭什么执牛耳?
历史的车轮滚滚向前,时间是最好的见证者。
去年10月,数据库市场发生了一件标志性事件:Amazon消费者业务正式完成对Oracle数据库的迁移工作,将近7500个Oracle数据库、75PB级数据库全部迁移到AWS 云数据库服务,包括Amaz…

数据驱动遇集成挑战,DELL EMC+Cloudera如何化解?
一个真实的现状。
过去银行的营销业务,通常是销售人员找关系、拉人头,费时费力不说,营销效果往往差强人意;如今的银行营销,精准的人物画像、不断迭代优化的营销模型、云柜员等基于数据驱动型的新业务场景纷纷上阵&…
数据湖+数据中台,金山云大数据平台竞争力如何?
随着疫情稳定,出行的解禁,正是拉动老客户消费和挖掘潜客的机会,那么银行在数字化时代的营销业务是如何实现的?首先在业务层面需要与各大电商平台、OTA、出行、O2O、线下餐饮、购物中心达成广泛的权益合作;之后汇聚内部…
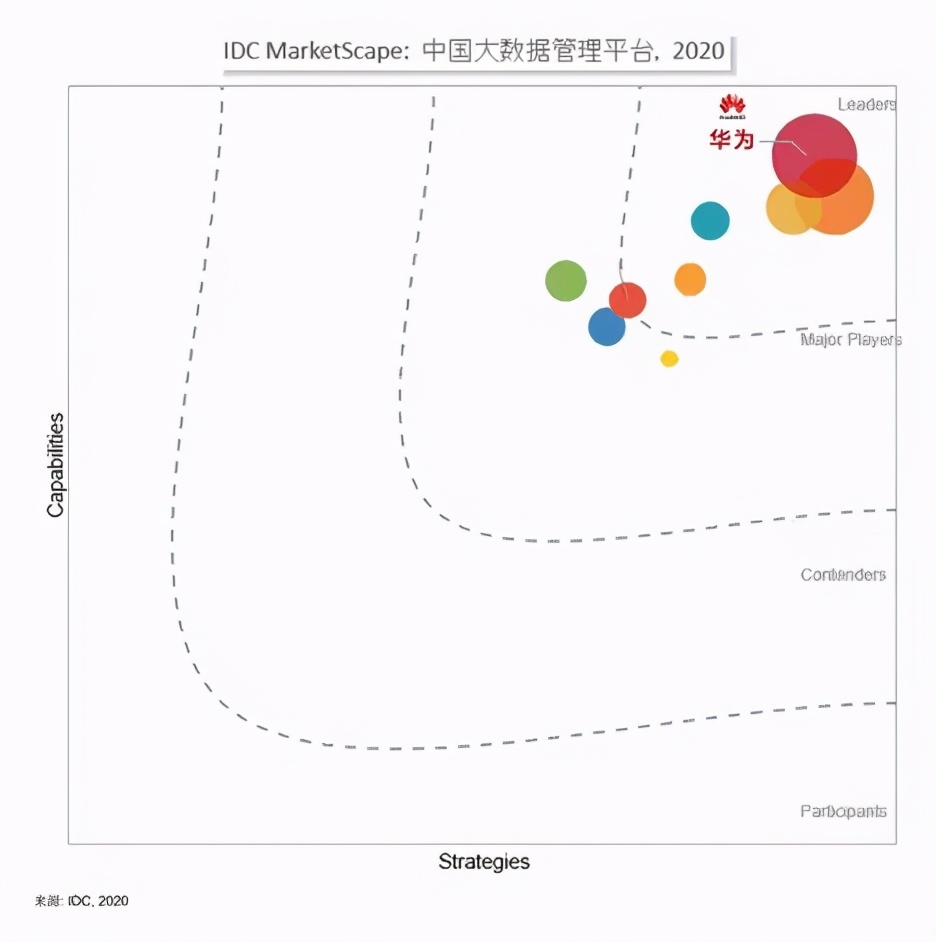
数据要素如何发挥价值,华为云展现新思路
“五年前,我很多客户的平均数据量大约为10TB,以ERP、CRM等数据为主;今天,客户的数据量达到PB级已成新常态,像零售、金融等行业,除了ERP、CRM这些结构化数据之外,还有大量各种行为/社交数据&…

Hudi学习 6:Hudi使用
准备工作: 1.安装hdfs
https://mp.csdn.net/mp_blog/creation/editor/109689143
2.安装spark
spark学习4:spark安装_hzp666的博客-CSDN博客
3.安装Scala
Hudi学习6:安装和基本操作_hzp666的博客-CSDN博客 spark-shell 写入和读取hudi 2.…
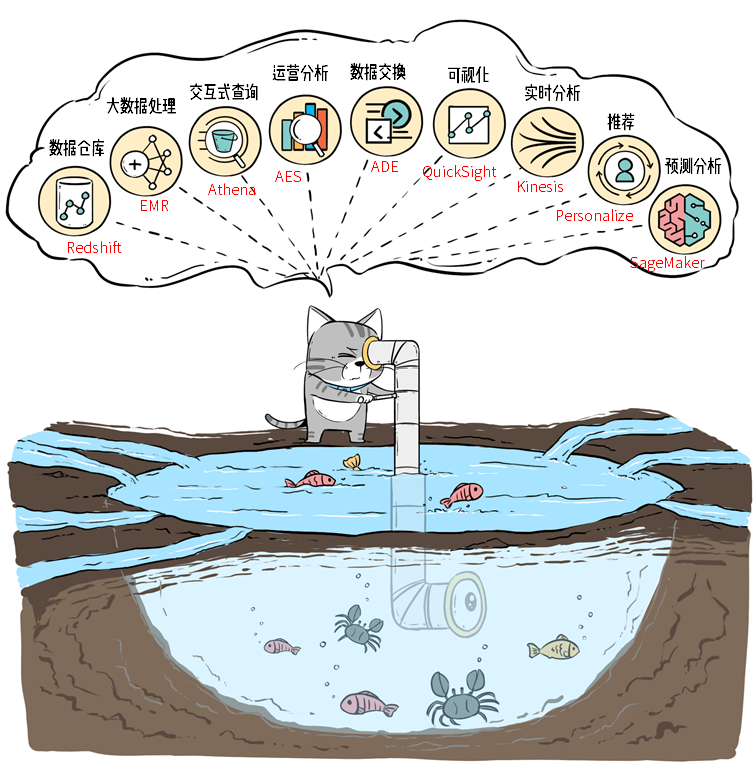
大数据技术16:数据湖和湖仓一体
前言:近几年大数据概念很多,数据库和数据仓库还没搞清楚,就又出了数据湖,现在又开始流行湖仓一体。互联网公司拼命造高大上概念来忽略小白买单的能力还是可以的。 1、数据库 数据库是结构化信息或数据的有序集合,一般以…

【LakeHouse】LakeHouse 架构指南
LakeHouse 架构指南 1.什么是数据湖,为什么需要数据湖2.数据湖、数据仓库和 LakeHouse 之间有什么区别3.数据湖的组件3.1 存储层 / 对象存储(AWS S3、Azure Blob Storage、Google Cloud Storage)3.2 数据湖文件格式(Apache Parque…

开源数据湖iceberg, hudi ,delta lake, paimon对比分析
Iceberg, Hudi, Delta Lake和Paimon都是用于大数据湖(Data Lake)或数据仓库(Data Warehouse)中数据管理和处理的工具或框架,但它们在设计、功能和适用场景上有所不同。 Iceberg: Iceberg是用于大型分析表的高性能格式。Iceberg将SQL表的可靠性和简易性带入到大数据领域,同…

记录几个Hudi Flink使用问题及解决方法
前言
如题,记录几个Hudi Flink使用问题,学习和使用Hudi Flink有一段时间,虽然目前用的还不够深入,但是目前也遇到了几个问题,现在将遇到的这几个问题以及解决方式记录一下
版本
Flink 1.15.4Hudi 0.13.0
流写
流写…
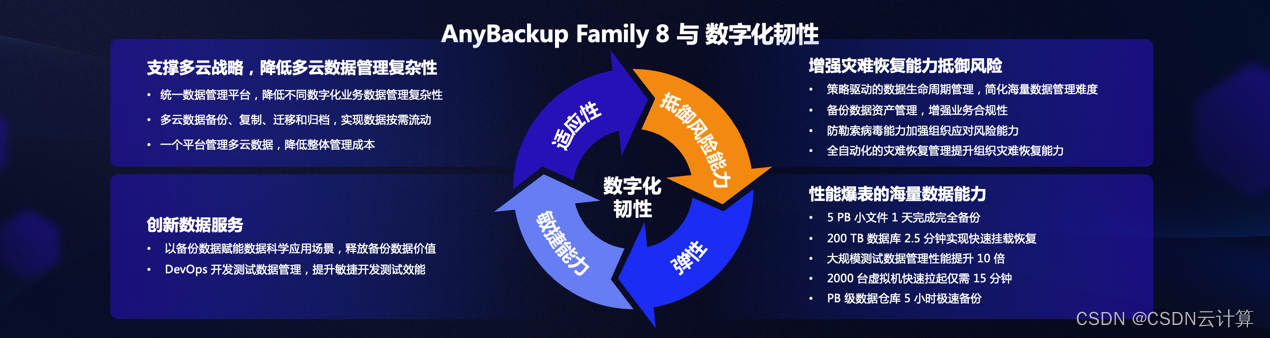
从数据备份保护到完整生命周期管理平台,爱数全新发布 AnyBackup Family 8
编辑 | 宋慧
出品 | CSDN 云计算 从2003年创业,开始做数据备份技术,爱数已经走过了近20年的时间。现在,数据的价值被越来越多的业界与用户看到,数据分析应用赛道近年一直持续火热。而现在的爱数在做的,已经从数据的备…

【大数据】数据湖:下一代大数据的发展趋势
数据湖:下一代大数据的发展趋势 1.数据湖技术产生的背景1.1 离线大数据平台(第一代)1.2 Lambda 架构1.3 Lambda 架构的痛点1.4 Kappa 架构1.5 Kappa 架构的痛点1.6 大数据架构痛点总结1.7 实时数仓建设需求 2.数据湖助力于解决数据仓库痛点问…
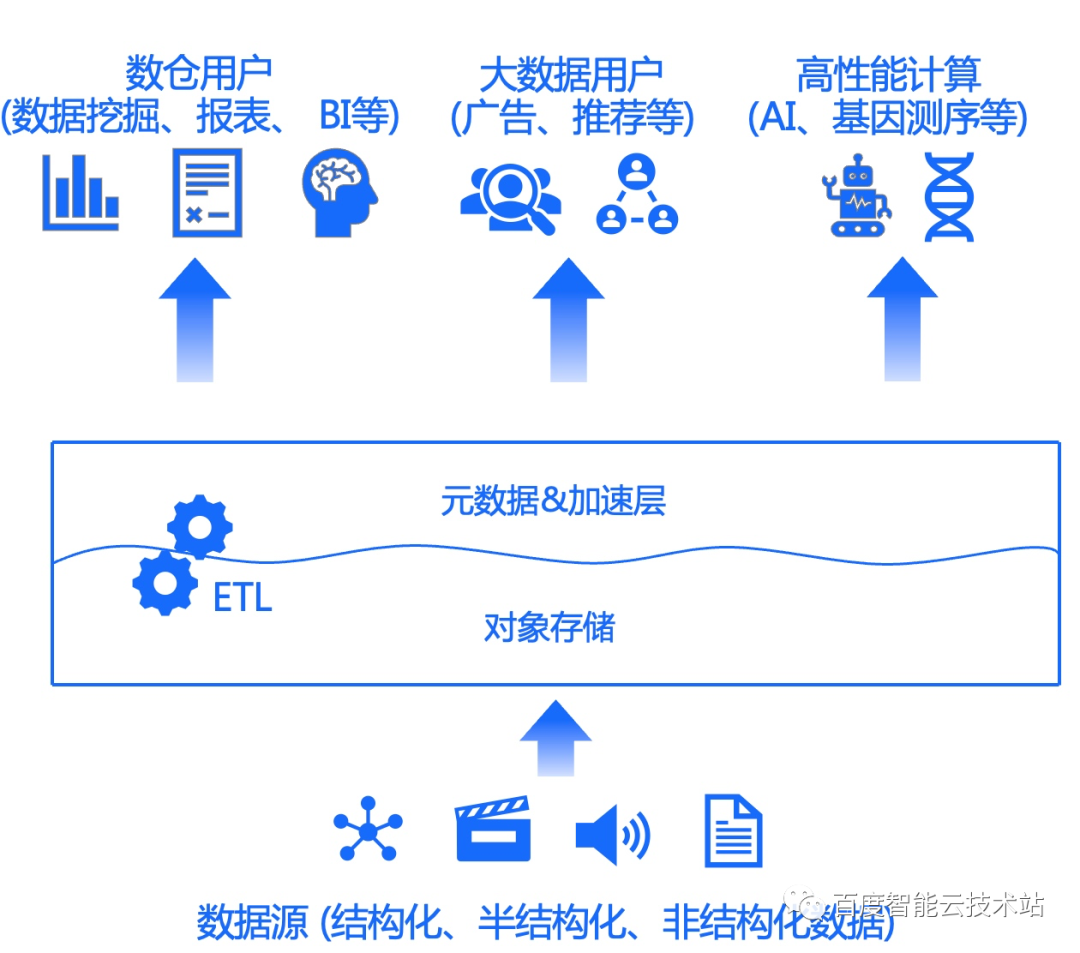
数据湖系列之一 | 你一定爱读的极简数据平台史,从数据仓库、数据湖到湖仓一体
1. 写在前面
我们身处一个大数据时代,企业的数据量爆炸式增长。如何应对海量数据存储和处理的挑战,建设好数据平台,对一个企业来说是很关键的问题。从数据仓库、数据湖,到现在的湖仓一体,业界建设数据平台的新方法和新…

Hudi源码 | Insert源码分析总结(二)(WorkloadProfile)
前言
接上篇文章:Hudi源码 | Insert源码分析总结(一)(整体流程),继续进行Apache Hudi Insert源码分析总结,本文主要分析上文提到的WorkloadProfile
版本
Hudi 0.9.0
入口
入口在上篇文章中讲到的BaseJavaCommitAc…
flink实战--FlinkSQl实时写入hudi表元数据自动同步到hive
简介 为了实现hive, trino等组件实时查询hudi表的数据,可以通过使用Hive sync。在Flink操作表的时候,自动同步Hive的元数据。Hive metastore通过目录结构的来维护元数据,数据的更新是通过覆盖来保证事务。但是数据湖是通过追踪文件来管理元数据,一个目录中可以包含多个版本…
Hudi基础 -- DML
文章目录1.Insert data(插入数据)2.Query data(查询数据)3.Time Travel Query4.Update(更新操作)5.MergeInto(合并插入)6.Hard Deletes(硬删除)7.Insert Over…
Hudi Java Client总结|读取Hive写Hudi代码示例
前言
Hudi除了支持Spark、Fink写Hudi外,还支持Java客户端。本文总结Hudi Java Client如何使用,主要为代码示例,可以实现读取Hive表写Hudi表。当然也支持读取其他数据源,比如mysql,实现读取mysql的历史数据和增量数据写…
Hudi系列20: Bucket索引
一. Bucket 索引概述
从 0.11 开始支持 默认的flink 流式 写入使用 state 存储索引信息: primary key 到 fileID 的映射关系。 当数据量比较大的时候, state的存储开销可能成为瓶颈, bucket 索引通过固定的 hash 策略, 将相同 key 的数据分配…
Apache Paimon基础记录
基本都是在官网的学习,简单记录一下其中的核心特点
Apache Paimon 官网
Apache Paimon | Apache Paimon
根据官网介绍去快速了解 paimon 是用来设计做什么,可以做什么,对比与其他数据湖有什么特点,如何使用
Paimon
特点
前身…
数据仓库 vs. 数据湖:解析两者的区别与优劣
在当今数字化时代,数据成为了企业最宝贵的资产之一。为了更好地管理和利用数据,企业需要建立合适的数据存储和管理系统。在这个过程中,数据仓库和数据湖成为了两种常见的选择。虽然它们都旨在帮助企业管理数据,但在实际应用中&…
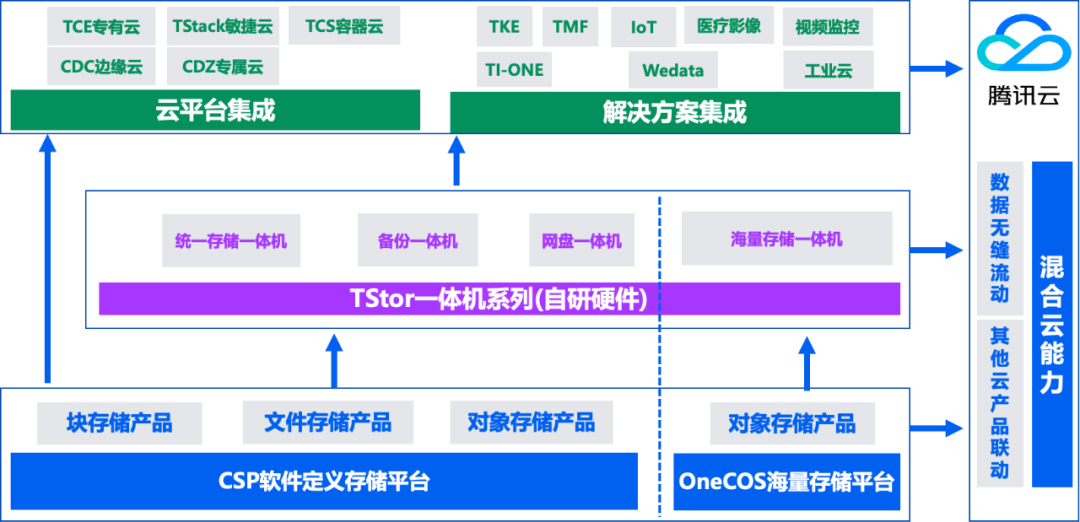
数据湖存储在大模型中的应用
9月5日,浪潮信息新产品“互联网AIGC”行业巡展在深圳举行。本次巡展以“智算 开新局创新机”为主题,腾讯云存储受邀分享数据湖存储在大模型中的应用,并在展区对腾讯云存储解决方案进行了全面的展示,引来众多参会者围观。
ChatGPT…
Apache Doris 1.2.3 Release 版本正式发布
亲爱的社区小伙伴们,我们很高兴地宣布,Apache Doris 于 2023 年 3 月 20 日迎来 1.2.3 Release 版本的正式发布!在新版本中包含超过 200 项功能优化和问题修复。同时,1.2.3 版本作为 1.2 LTS 的迭代版本,更加稳定易用&…

数据湖仓一体化架构:探究新一代数据处理的可能性
一、引言
随着大数据的快速发展,企业不断寻求高效、灵活和经济的方法来处理和管理海量数据。在这种背景下,数据湖和数据仓库这两种不同的架构模式各自展现出其独特的优势。而数据湖仓一体化架构,是对这两种模式优势的综合,为企业…

Hudi系列25: Flink SQL使用checkpoint恢复job异常
文章目录 一. 通过Flink SQL将MySQL数据写入Hudi二. 模拟Flink任务异常2.1 手工停止job2.2 指定checkpoint来恢复数据2.3 整个yarn-session上的任务恢复 三. 模拟源端异常3.1 手工关闭源端 MySQL 服务3.2 FLink任务查看 FAQ:1. checkpoint未写入数据2. checkpoint 失败3. 手工取…
Hudi Spark SQL Call Procedures学习总结(一)(查询统计表文件信息)
前言
学习总结Hudi Spark SQL Call Procedures,Call Procedures在官网被称作存储过程(Stored Procedures),它是在Hudi 0.11.0版本由腾讯的ForwardXu大佬贡献的,它除了官网提到的几个Procedures外,还支持其…
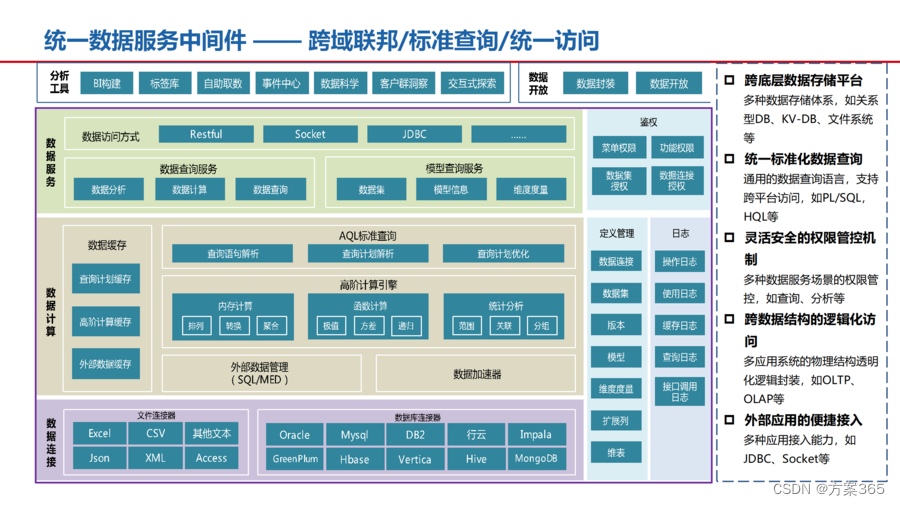
大数据湖体系规划与建设方案:PPT全文51页,附下载
关键词:大数据解决方案,数据湖解决方案,数据数仓建设方案,大数据湖建设规划,大数据湖发展趋势
一、大数据湖体系规划与建设背景
在传统的企业信息化建设中,各个业务系统通常是独立建设的,导致…
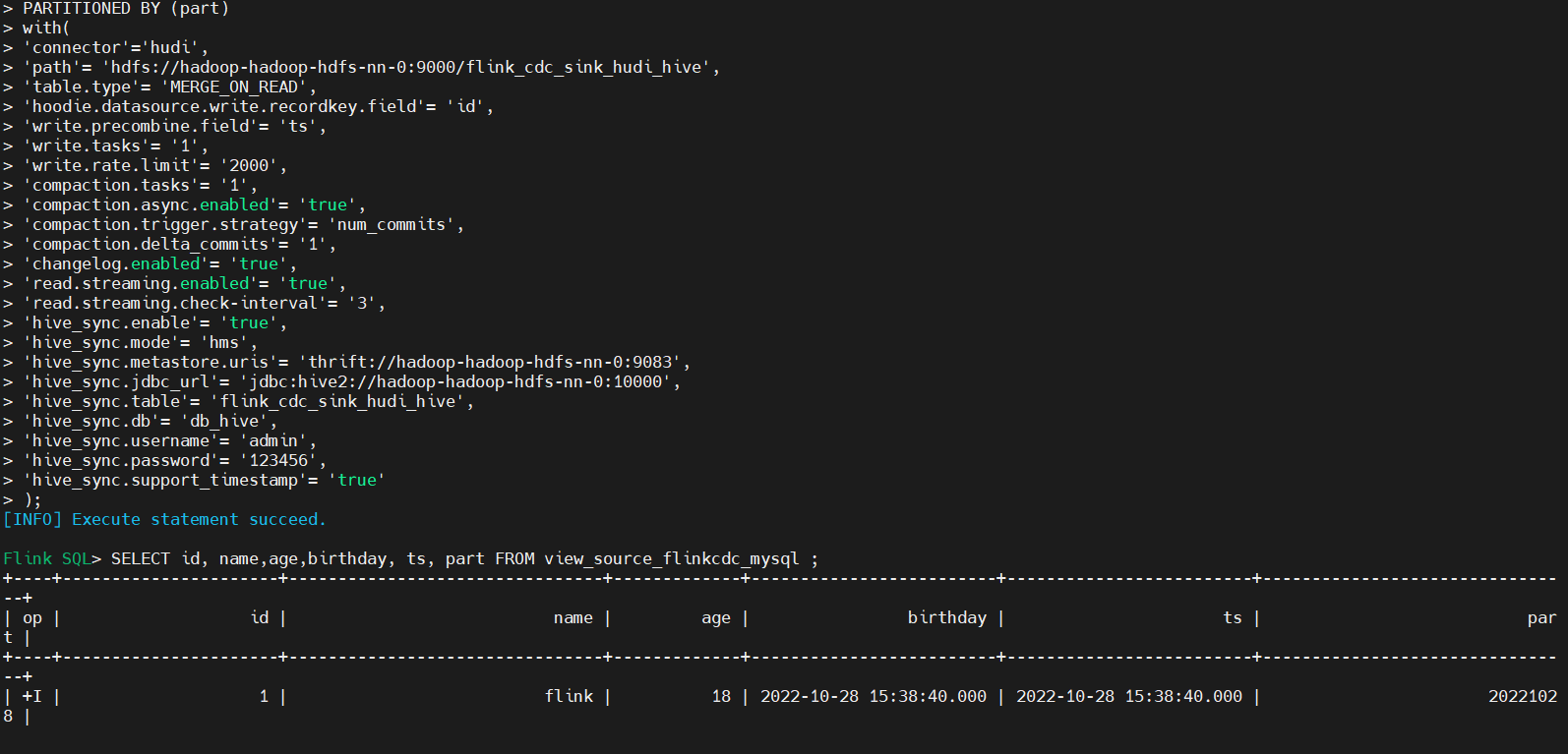
大数据Hadoop之——Apache Hudi 数据湖实战操作(FlinkCDC)
文章目录一、概述二、Hudi 数据管理1).hoodie文件2)数据文件三、数据存储四、Hive 与 Hudi 集成使用1)安装mysql数据库2)安装 Hive1、下载2、配置3、解决Hive与Hadoop之间guava版本的差异4、下载对应版本的mysql驱动包5、初始化元…

数据湖Iceberg介绍和使用(集成Hive、SparkSQL、FlinkSQL)
文章目录 简介概述作用特性数据存储、计算引擎插件化实时流批一体数据表演化(Table Evolution)模式演化(Schema Evolution)分区演化(Partition Evolution)列顺序演化(Sort Order Evolution&…
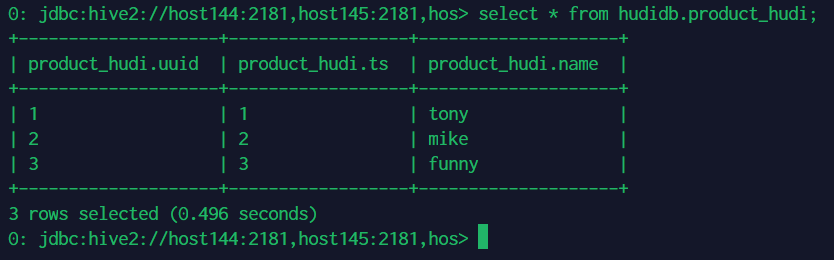
【大数据】Hudi HMS Catalog 完全使用指南
Hudi HMS Catalog 完全使用指南 1.Hudi HMS Catalog 基本介绍2.在 Flink 中写入数据3.在 Flink SQL 中查看数据4.在 Spark 中查看数据5.在 Hive 中查看数据 1.Hudi HMS Catalog 基本介绍
功能亮点:当 Flink 和 Spark 同时接入 Hive Metastore(HMS&#…

下一代存储解决方案:湖仓一体
文章首发地址
湖仓一体是将数据湖和数据仓库相结合的一种数据架构,它可以同时满足大数据存储和传统数据仓库的需求。具体来说,湖仓一体可以实现以下几个方面的功能:
数据集成: 湖仓一体可以集成多个数据源,包括结构…
6 Hive引擎集成Apache Paimon
更多Paimon数据湖内容请关注:https://edu.51cto.com/course/35051.html
在实际工作中,我们通查会使用Flink计算引擎去读写Paimon,但是在批处理场景中,更多的是使用Hive去读写Paimon,这样操作起来更加方便。
前面我们…
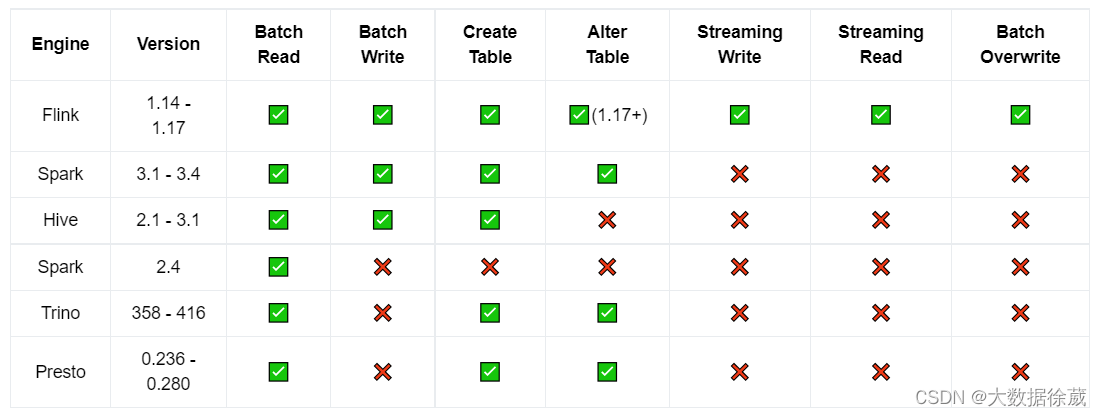
1 快速了解Paimon数据湖核心原理及架构
1.1 什么是Apache Paimon
Apache Paimon的前身属于Flink的子项目:Flink Table Store。
目前业内主流的数据湖存储项目都是面向批处理场景设计的,在数据更新处理时效上无法满足流式数据湖的需求,因此Flink社区在2022年的时候内部孵化了 …
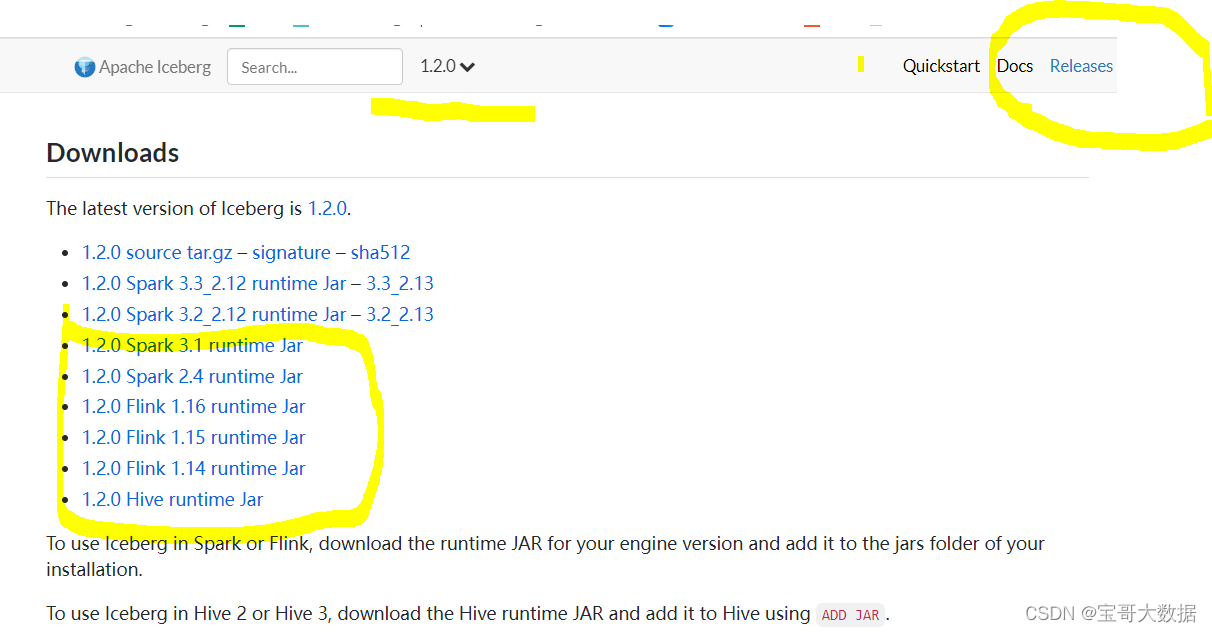
Iceberg编译 及 与 Spark、Flink整合
一、准备工作
1.1、安装gradle
由于iceberg采用gradle来管理项目, 在编译之前需要安装gradle 检查jdk版本, gradle需要jdk8以及以上版本
wget https://services.gradle.org/distributions/gradle-8.1-rc-3-all.zip
unzip gradle-8.1-rc-3-all.zip 配置环境变量
vi /etc/pro…
入门大纲 我为什么使用delta-io 数据湖 替代hive
1 大厂背书
databricks宣布把delta-io共享给apache基金会 并且delta-io从以前打杂的0.x版本升级为1.x 随后就是bug的各种修复和新功能的增加.
release note可以看: Releases delta-io/delta GitHub 2 并发控制(解决了多任务并发读写表时的 读写冲突)
hive/spark 如果多个任…

【大数据】Hudi 核心知识点详解(一)
😊 如果您觉得这篇文章有用 ✔️ 的话,请给博主一个一键三连 🚀🚀🚀 吧 (点赞 🧡、关注 💛、收藏 💚)!!!您的支持 &#x…

4 Paimon数据湖之Hive Catalog的使用
更多Paimon数据湖内容请关注:https://edu.51cto.com/course/35051.html
Paimon提供了两种类型的Catalog:Filesystem Catalog和Hive Catalog。
Filesystem Catalog:会把元数据信息存储到文件系统里面。Hive Catalog:则会把元数据…

2 快速上手使用Paimon数据湖
2.1 基于Flink SQL操作Paimon
在这里我们基于Flink 1.15(ON YARN)、Paimon 0.5版本开发一个案例。 注意:想要使用Paimon是非常简单的,不需要复杂的安装部署,只需要使用一个jar包即可对它进行操作。 我们在使用Paimon的时候其实也可以把它简单…
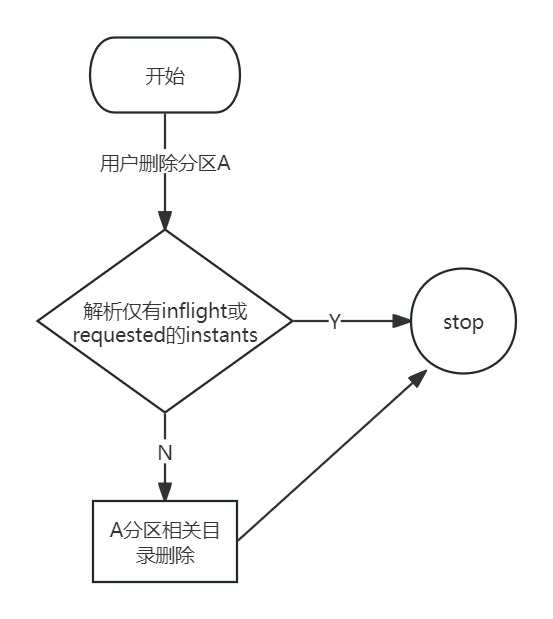
Hudi 在 vivo 湖仓一体的落地实践
作者:vivo 互联网大数据团队 - Xu Yu 在增效降本的大背景下,vivo大数据基础团队引入Hudi组件为公司业务部门湖仓加速的场景进行赋能。主要应用在流批同源、实时链路优化及宽表拼接等业务场景。
一、Hudi 基础能力及相关概念介绍
1.1 流批同源能力
与H…

玩转大数据7:数据湖与数据仓库的比较与选择
1. 引言
在当今数字化的世界中,数据被视为一种宝贵的资源,而数据湖和数据仓库则是两种重要的数据处理工具。本文将详细介绍这两种工具的概念、作用以及它们之间的区别和联系。
1.1. 数据湖的概念和作用
数据湖是一个集中式存储和处理大量数据的平台&a…

DataFunSummit:2023年数据湖架构峰会-核心PPT资料下载
一、峰会简介
现今,很多企业每天都有PB级的数据注入到大数据平台,经过离线或实时的ETL建模后,提供给下游的分析、推荐及预测等场景使用。面对如此大规模的数据,无论是分析型场景、流批一体、增量数仓都得益于湖仓一体等数据湖技术…
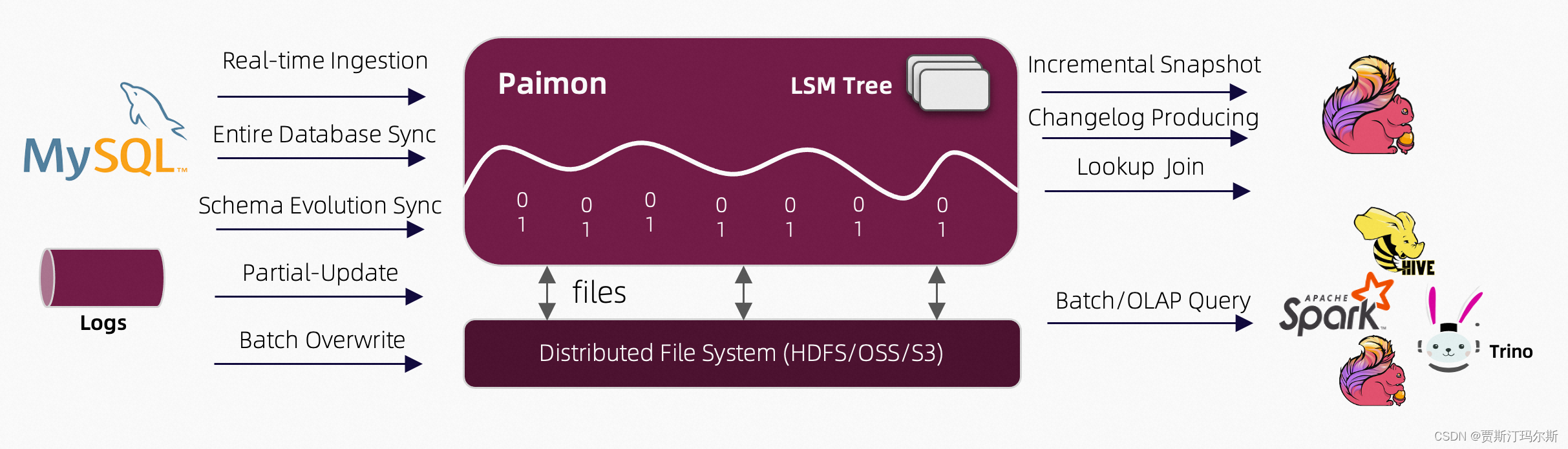
Apache Paimon实时数据糊介绍
Apache Paimon 是一种湖格式,可以使用 Flink 和 Spark 构建实时 数据糊 架构,用于流式和批处理操作。Paimon 创新地将湖格式和 LSM(日志结构合并树)结构相结合,将实时流式更新引入湖架构中。
Paimon 提供以下核心功能: 实时更新: 主键表支持大规模更新的写入,具有非常…
【大数据】Apache Iceberg 概述和源代码的构建
Apache Iceberg 概述和源代码的构建 1.数据湖的解决方案 - Iceberg1.1 Iceberg 是什么1.2 Iceberg 的 Table Format 介绍1.3 Iceberg 的核心思想1.4 Iceberg 的元数据管理1.5 Iceberg 的重要特性1.5.1 丰富的计算引擎1.5.2 灵活的文件组织形式1.5.3 优化数据入湖流程1.5.4 增量…
数据湖十年风雨路,云服务商缘何脱颖而出
数据湖,是一个并不新颖却越来越被用户看重的名词。
从2010年Pentaho公司的创始人兼首席技术官詹姆斯狄克逊(James Dixon)首次提出数据湖的概念开始,数据湖十年发展之路可谓是兜兜转转、起起伏伏。在这期间,既有开源厂商们提出的各种营销理念…
湖仓管理系统 Amoro部署
简介
Apache Amoro(incubating) 是一个构建在 Apache Iceberg 等开放数据湖表格之上的湖仓管理系统,提供了一套可插拔的数据自优化机制和管理服务,旨在为用户带来开箱即用的湖仓使用体验。
Amoro 的愿景是依托于 Apache Iceberg、Apache Paimon 等新型数据湖表格式的基础功…

从公有云对象存储迁移到回私有化 MinIO需要了解的所有信息
我们上一篇文章《如何从 AWS S3 遣返到 MinIO》的反响非常出色 - 我们已经接到了数十个企业的电话,要求我们提供遣返建议。我们已将这些回复汇总到这篇新文章中,其中我们更深入地研究了与遣返相关的成本和节省,以便您更轻松地进行自己的分析。…
Scala操作hudi
文章目录Scala操作hudi1、启动客户端2、配置信息3、 创建数据表4、插入数据5、查询数据6、更新数据7、增量查询8、时间点查询9、删除数据10、覆盖写入Scala操作hudi
1、启动客户端
//spark3.1
spark-shell \--packages org.apache.hudi:hudi-spark3.1.2-bundle_2.12:0.10.1,o…

尚硅谷大数据技术-数据湖Hudi视频教程-笔记01【概述、编译安装】
大数据新风口:Hudi数据湖(尚硅谷&Apache Hudi联合出品) B站直达:https://www.bilibili.com/video/BV1ue4y1i7na 尚硅谷数据湖Hudi视频教程百度网盘:https://pan.baidu.com/s/1NkPku5Pp-l0gfgoo63hR-Q?pwdyyds阿里…
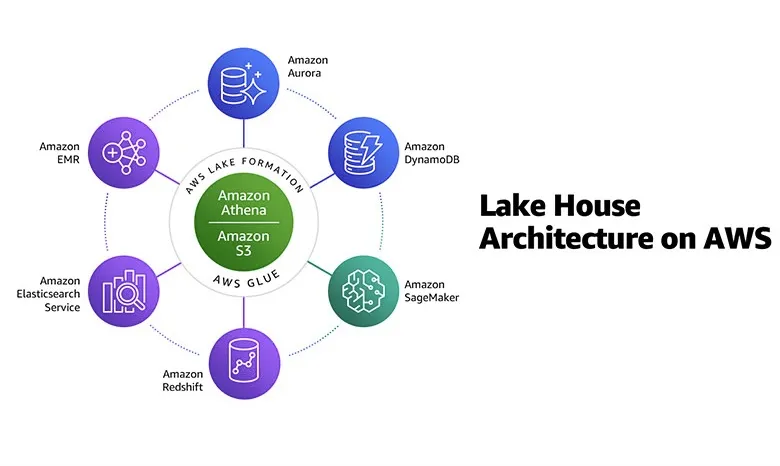
消除数据重力,从智能湖仓(Lake House)读懂实现数据价值的未来
忽如一夜春风来,湖仓架构似花开。
今年的云计算市场,似乎谁不提湖仓架构谁就落伍。为何湖仓架构这么火?如今看来,数据湖和数据仓库加速互动,看似偶然、其实必然。
曾几何时,很多用户因为本地数据仓库方案…
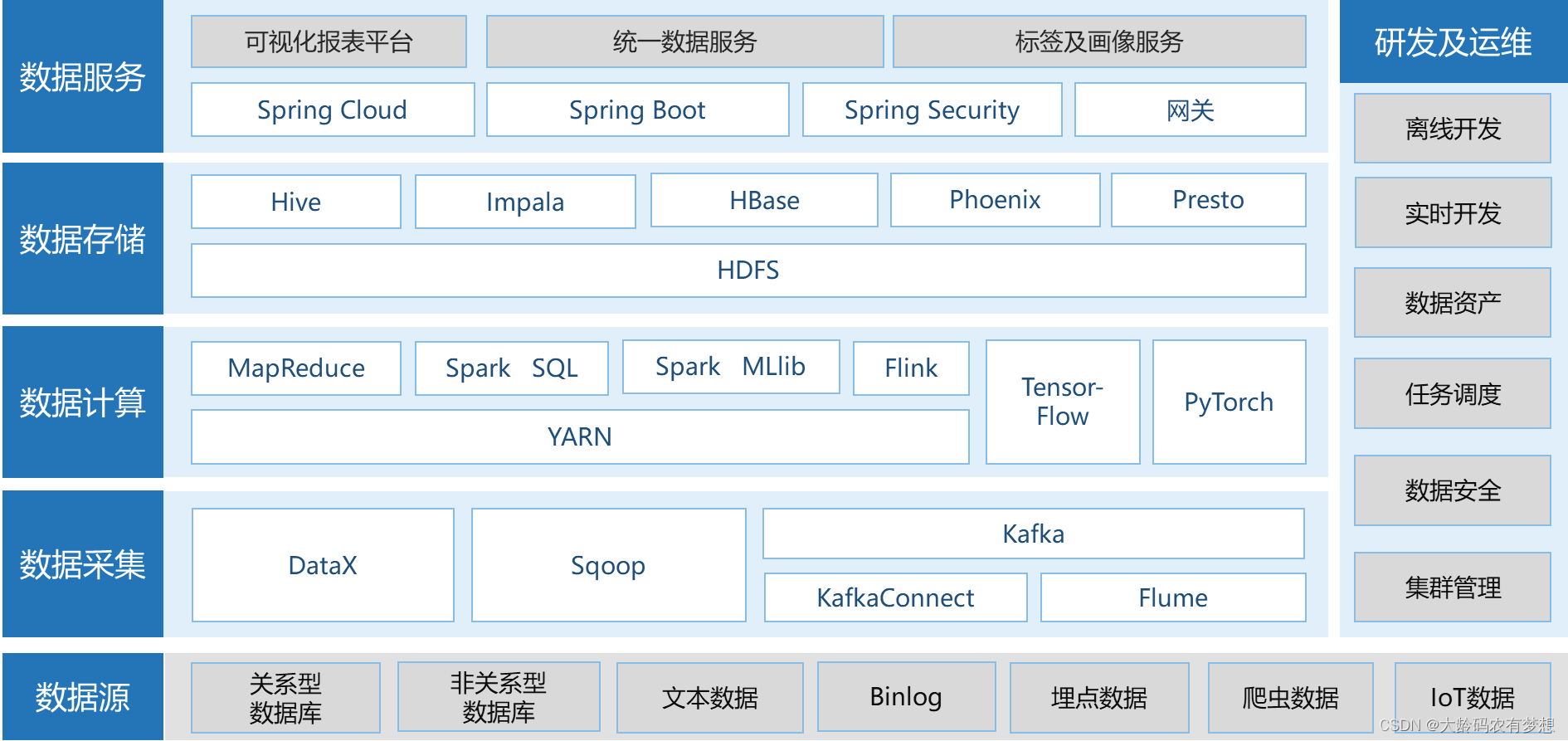
企业级数据中台应用架构和技术架构
一、什么是数据中台
数据中台是一种将企业沉睡的数据变成数据资产,持续使用数据、产生智能、为业务服务,从而实现数据价值变现的系统和机制。通过数据中台提供的方法和运行机制,形成汇聚整合、提纯加工、建模处理、算法学习,并以…
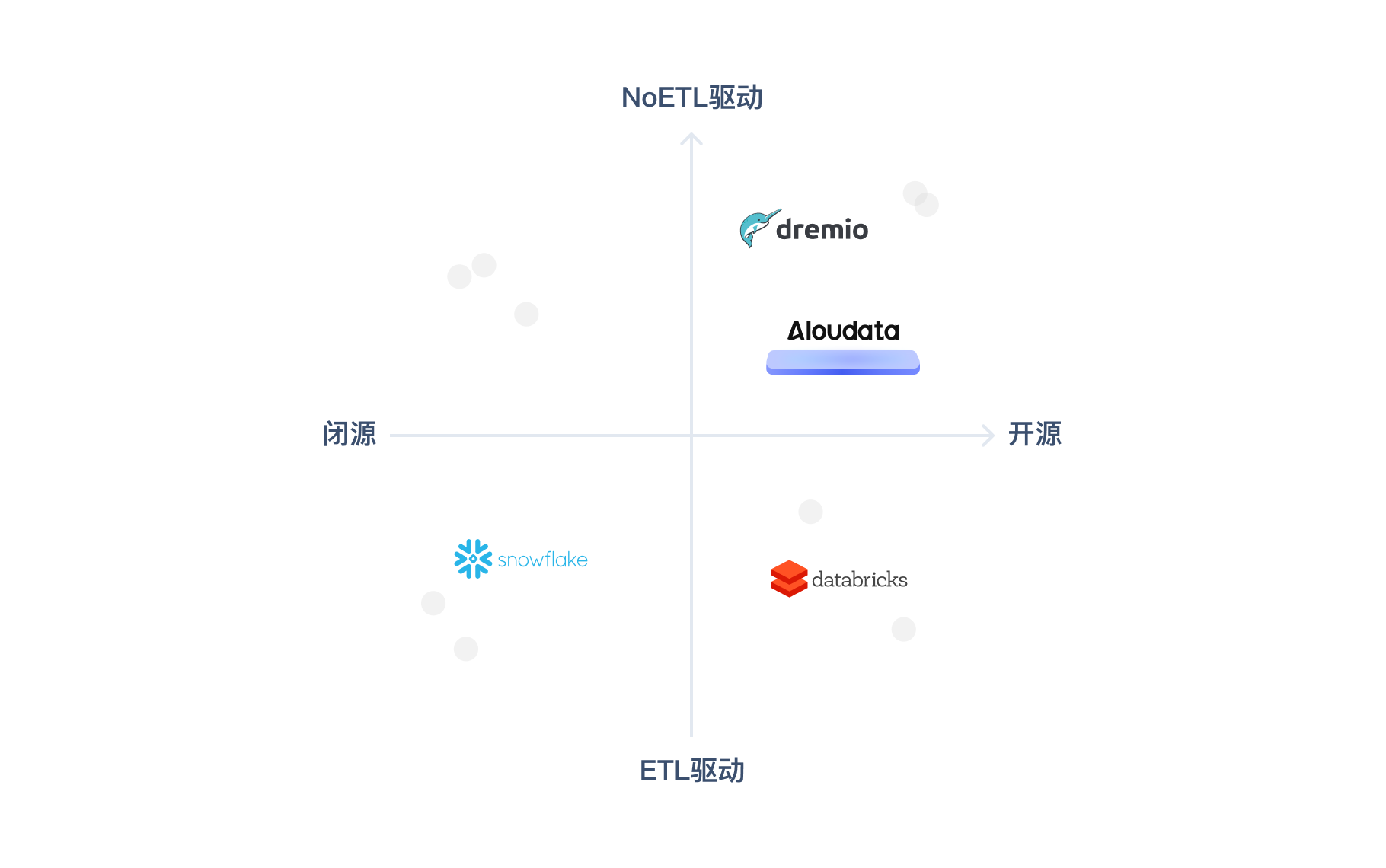
Aloudata创始人周卫林:以NoETL叩开数据平台变革之门
对数据智能赛道的创业者而言,这是最好的时代,是最需要创新精神也拥有最多可能的时代。
过去20年间,互联网和移动互联网的浪潮深刻改变了社会的各个方面,无论线上还是线下,人们的行为都发生了深刻的变化,企…
数据仓库和数据湖的区别
数据仓库和数据湖是两种不同的数据存储和管理架构,它们有以下区别:
1.数据结构:数据仓库采用结构化的数据模型,通常是规范化的关系型数据库,其中数据以表格形式组织,使用预定义的模式和架构。而数据湖则是…

数据湖和数据仓库区别介绍
从数据仓库到数据湖
仓库和湖泊
仓库是人为提前建造好的,有货架,还有过道,并且还可以进一步为放置到货架的物品指定位置。 而湖泊是液态的,是不断变化的、没有固定形态的,基本上是没有结构的,湖泊可以是由…

【数据湖架构】数据湖101:概述
数据湖是非结构化和结构化数据池,按原样存储,没有特定的目的,可以建立在多种技术上,如Hadoop,NoSQL,Amazon Simple Storage Service,关系数据库或各种组合根据一份名为“什么是数据湖”的白皮书…
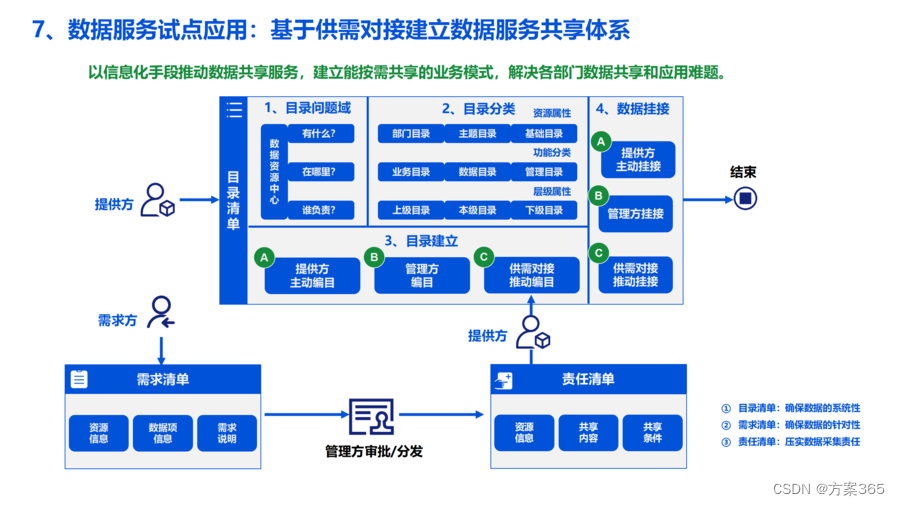
大数据湖及应用平台建设解决方案:PPT全39页,附下载
关键词:大数据湖建设,集团大数据湖,大数据湖仓一体,大数据湖建设解决方案
一、大数据湖定义
大数据湖是一个集中式存储和处理大量数据的平台,主要包括存储层、处理层、分析层和应用层四个部分。
1、存储层ÿ…
SparkSQL操作hudi
文章目录SparkSQL操作hudi1、登录2、创建普通表3、创建分区表4、从现有表创建表5、用查询结果创建新表(CTAS)6、插入数据7、查询数据8、修改数据9、合并数据10、删除数据11、覆盖写入12、修改数据表13、hudi分区命令SparkSQL操作hudi
1、登录
#spark 3.1
spark-sql --package…
亚马逊云科技最新分享:人、流程、工具全链路数据安全合规
数据已经是现代发明和创新之源。 企业需要人—流程—工具全链路的数据安全合规。 出品 | CSDN 云计算 端到端、全栈,是近两年我们听到云巨头亚马逊云科技提到最多的架构思路。现在,已经成为生产要素的数据,重要性被提到的非常高的高度&#x…